

Hier soir, j'ai importé les données des logs de NginX et d'Apache sur Piwik. Si vous ne comprenez pas ce que ça veut dire, tant mieux, cet article vous sera utile. Toujours est-il que le résultat de cette importation m'a mis involontairement dans la position d'un agent de la NSA : j'avais sous les yeux le trafic quasiment complet, page par page, de presque 8'000 visites sur des sites qui n'avaient rien à voir avec les nôtres. Une seule raison à cela : le "hotlink".
Cet article a pour objectif de présenter une utilisation très concrète de cette brèche de confidentialité, pourtant si aisément ouverte par des millions de webmasters de par le monde.
Hotlink
Connu depuis l'aube d'Internet, "hotlink" est un terme presque désuet qui désigne l''utilisation de ressources (images, vidéos, scripts, ...) hébergées sur un serveur n'ayant aucun rapport avec le site web qui les utilise. Cette pratique était initialement découragée, parce qu'elle consommait la bande passante du serveur ainsi pillé, via un autre site qui pouvait profiter de son contenu sans brûler son propre forfait. Il faut se rappeler qu'il y a dix ans, la bande passante était un des principaux goulots d'étranglement pour les "petits" sites web : les hébergeurs offraient quelque chose comme 30 Go de trafic mensuel. Si vous aviez la mauvaise idée de publier une image de 150 Ko sur votre site web et qu'un site populaire l'utilisait à vos dépens, il n'aurait suffi que 200'000 visites sur un mois pour engloutir l'intégralité des 30 Go à votre disposition. La solution à ce problème était de bloquer, au niveau du serveur, les accès provenant de référents "non-accrédités".

Aujourd'hui, deux choses ont changé : la bande passante se fait plus généreuse et les grosses entreprises, dans leur tentative de centraliser Internet, sont plus qu'heureuses de vous proposer des services hébergés par leur soin, qu'il vous suffit d'intégrer à vos sites web. Dans ce cas, on parle de "CDN"((Content Delivery Network, des serveurs optimisés pour la vitesse, dont le seul but est de dupliquer les ressources de votre site et de les proposer plus rapidement à vos visiteurs)), de "Widgets"((Des petits morceaux d'un site externe, souvent généré par du javascript qui va télécharger des ressources supplémentaires sur les sites de l'entreprise qui met des widgets à disposition.)) ou encore de "Webservices". Difficile de s'insurger contre ces pratiques : en soi, elles sont les fondations du "Web 2.0", de l'interopérabilité entre sites web et de la standardisation des communications sur Internet. C'est grâce à elles que nous sommes allés si loin - pour le meilleur comme pour le pire. Il faut cependant garder en tête les implications de l'utilisation de ces ressources externes et, surtout, à quel point elles peuvent trahir votre confidentialité.
Retour sur les bases
La suite de cet article va entrer dans des détails techniques. Si vous n'êtes pas versés là-dedans, accrochez-vous : l'apprentissage en vaut la peine.
Trackers publicitaires
Si vous suivez l'actualité des technologies, vous êtes sans doute au courant des nombreux débats qui agitent le web concernant la vie privée. Depuis quelques années (tout s'est accéléré depuis les révélations d'Edward Snowden), divers groupements d'utilisateurs avertis, d'annonceurs consciencieux ou encore d'entreprises s'opposent à la multiplication des cookies, qui peuvent être utilisés pour traquer discrètement les gens sur Internet. Ces cookies sont installés par Javascript, un langage exécuté par votre navigateur. Aujourd'hui, il est possible d'étendre les fonctionnalités de nos navigateurs avec des plug-ins comme Ghostery, uBlock ou Disconnect : ceux-ci désactivent les trackers les plus communs, détectés via des listes régulièrement mises à jour, à l'instar des bases de données virales employées par les anti-virus. Et croyez-moi, éradiquer tous les trackers malsains qui pullulent sur bon nombre de sites permet un gain de performance et de bande passante absolument dramatique, en plus de protéger votre vie privée contre des agences (publicitaires ou gouvernementales) qui ne vous veulent définitivement pas que du bien.
Si "aller sur un site" était l'équivalent de "faire l'amour avec quelqu'un", alors ces plugins qui bloquent les scripts sont les préservatifs qui vont empêcher votre navigateur - et votre anonymat sur Internet - de clamser d'une maladie vénérienne. Utilisez-les. D'une certaine manière, il est triste d'avoir à bloquer des "trackers" comme Piwik (utilisé sur ce blog), dont les données ne servent généralement qu'à mesurer l'audience d'un site et optimiser son ergonomie. Mais à choisir entre limiter les statistiques d'un site comme le mien ou moisir l'intégralité des utilisateurs du web, la première solution s'impose comme un moindre mal.
Logs des serveurs vs Page tagging
Les techniques de tracking mentionnées ci-dessus utilisent presque toutes la même méthode : du code javascript, interprété par votre navigateur, envoie des données parfois assez sophistiquées à un serveur distant, qui les traite à des fins multiples (de simples statistiques pour webmasters au profilage crados et malsain pour annonceurs). Dans le monde du "Web Analytics", on appelle cette technique "Page Tagging". Si vous bloquez javascript - ou du moins, certains codes spécifiques à ces trackers - les scripts deviennent inopérants.
Pour autant, ne vous pensez pas à l'abri. Il existe une autre menace presque aussi dangereuse pour votre vie privée : les logs des serveurs, qui peuvent également servir de base à une analyse de votre trafic.
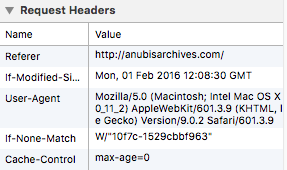
Reprenons depuis le début. HTTP (HyperText Transfert Protocole) est le protocole de référence employé sur Internet. À l'instar de leur équivalent de la vie réelle, les protocoles informatiques sont une succession de règles à suivre pour les ordinateurs, afin d'échanger des informations. HTTP est prévu pour un client (votre navigateur) et un serveur (un ordinateur distant) : le client se présente via une série d'en-têtes discrètes, le serveur acquiesce et retourne les ressources demandées par le client. Or donc, les serveurs modernes (entre autres, Apache et NginX) enregistrent chaque requête effectuée par leurs clients. Par défaut, ces enregistrements contiennent :
- l'adresse IP du client
- l'utilisateur (rarement applicable)
- la date et heure de la requête
- la ressource demandée
- les codes associées à la requête
- le référent (champs "Referer" de l'en-tête)
- les informations sur le navigateur (champs "User-Agent" de l'en-tête).
En gros, voilà le résultat d'une seule requête :
51.255.65.39 - - [25/Feb/2016:09:23:17 +0100] "GET /jdr/masquesanubis/doku.php?id=pnj:neris&ns=place&tab_files=files&do=media&tab_details=history&image=doc%3Aallutigre.png HTTP/1.1" 200 4841 "-" "Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://ahrefs.com/robot/)"
Il existe des logiciels, comme Piwik ou AwStats, qui permettent d'importer et d'analyser ces logs. Ils en extraient des statistiques d'utilisation du site web. Par curiosité, j'ai aspiré les quelques 150'000 lignes qui composaient le dernier fichier de log de notre serveur sur Piwik. Et là, je me suis retrouvé avec le trafic de milliers de personnes anonymes, sur des sites inconnus dont je n'ai absolument pas le contrôle. Oui, c'est aussi terrible que ça !
Ce qui s'est passé
Il s'avère que Ddril, mon partenaire et co-propriétaire de l'Organisation Très Secrète, est particulièrement investi dans la communauté du jeu de rôle sur forum. Cette communauté fonctionne énormément sur références : les annuaires de liens, les partenariats et le bouche-à-oreille font partie des meilleures méthodes pour attirer des rôlistes sur un nouveau forum. Ces "alliances" prennent généralement la forme d'un logo ou d'une bannière, situé/e quelque part sur la page et dirigeant vers le forum partenaire.
Or il s'avère également que beaucoup trop de webmasters se contentent de "hotlinker" les logos, plutôt que de les héberger directement sur leur serveur. Si vous avez suivi cet article, vous savez ce qu'il en résulte : chaque page ouverte par un visiteur et sur laquelle figure le logo hotlinké génère une requête HTTP vers le serveur hébergeant l'image. Cette requête est enregistrée, avec toutes les informations qui lui sont liées, y compris l'adresse exacte de la page sur laquelle se trouve le visiteur. À posteriori, on peut donc reconstituer avec exactitude le cheminement dudit visiteur, qu'on corrèle à son adresse IP (qui permet de localiser la personne avec plus ou moins de précision). En gros : sans avoir besoin de Javascript, il est possible de traquer avec pas mal de précision n'importe qui. Et là, on parle de presque 8'000 visites... sur deux jours.
Comment se prémunir
Soyons clairs : les logs des serveurs sont des outils précieux pour comprendre d'éventuelles défaillances. N'attendez pas que les sysadmins réduisent la précision de ces logs juste pour vos beaux yeux. Il serait envisageable de n'enregistrer que les informations des visiteurs au comportement étrange (beaucoup trop de requêtes dans un temps réduit, par exemple), mais d'ici à ce que tous les serveurs du monde soient mis à jour pour adopter un tel comportement, nous aurons tous des cheveux blancs.

La responsabilité de cette brèche dans la vie privée de milliers de personnes incombent exclusivement aux webmasters inconscients qui utilisent des ressources externes à tire-larigot, en s'économisant toute réflexion sur les conséquences de ce comportement. De base, évitez leurs sites comme la peste.
À défaut, il existe quelques méthodes pour se protéger : sur Firefox, par exemple, il est possible de bloquer le champs "Referer" de vos en-têtes HTTP. Vous éviterez ainsi que les logs n'enregistrent votre URL et vous traque de page en page. Malheureusement, ce comportement fait parfois planter les sites qui utilisent ce champs (pour éviter le deep linking, par exemple). L'idéal serait de soustraire vos véritables données pour les remplacer par de fausses informations : je n'ai pas suffisamment fouillé le web à ce sujet, mais ça doit déjà exister. Vous pouvez également utiliser des plugins de navigateur, qui offrent la possibilité de bloquer les ressources chargées sur des sites tiers : là encore, vous encourrez le risque de zapper du contenu utile à l'affichage de la page, mais vous pourrez les valider manuellement si nécessaire. Au moins serez-vous informés.
Conclusions
En ce qui concerne les données absorbées par Piwik, je les ai effacées : au-delà des raisons éthiques évidentes, les quelques 8'000 enregistrements en deux jours équivalaient, en termes de taille, à presque deux ans de trafic sur mon blog. Beaucoup d'espace perdu pour rien.
Si vous disposez d'un site web et que vous vous souciez un minimum de l'anonymat de vos visiteurs, activez les outils d'analyse de votre navigateur et passez en revue toutes vos pages. Pour chaque ressource chargée en-dehors de votre site, posez-vous la question de savoir si elles sont réellement nécessaires et surtout, si leur hébergeur est digne de confiance. Vous exposez tous vos visiteurs à des risques.
À bon entendeur !