

Je m'étais promis de me consacrer à des projets non-informatiques au moins jusqu'au début octobre, mais la tentation s'avère trop forte : le temps passé sur mes statistiques Piwik m'a donné envie d'améliorer la manière dont les "rebonds" sont comptabilisés. Ce court article illustre une solution personnalisée pour ce blog, qui peut néanmoins être adaptée à tous les sites utilisant Piwik, voire pour ceux qui utilisent Google Analytics.

Les flèches représentent des événements, sur le dashboard "Visitors in Real-Time".
Dans mon billet précédent, je tentais une définition des "rebonds" dans le cadre du Web analytics, mais ces explications manquaient de précision. Théoriquement, un "rebond" est une visite qui ne génère que peu d'intérêt pour la personne derrière l'écran : cette personne tombe sur votre site, jette un regard rapide à la première page et disparaît aussitôt. Les systèmes de Web analytics modernes doivent traduire ce désintérêt en métriques. Comment comprendre qu'un utilisateur n'est pas intéressé par le contenu d'un site ? Pour Piwik, un "rebond" ne se limite pas forcément à une seule page vue, mais à une seule action. La différence est de taille : par exemple, un visiteur qui télécharge un fichier sur une page ne sera pas comptabilisé comme rebond. Encore faut-il que votre page propose quelque chose à télécharger !
Et voilà à quoi ressemble un événement sur le détail d'une visite.
J'essaie actuellement de mesurer l'intérêt que portent mes visiteurs/se/s aux articles de ce blog. Le problème, c'est que certaines personnes me suivent via Twitter, Wordpress ou Google+. Lorsque je poste un article, ces personnes cliquent sur le lien, lisent l'article (ou pas...) et repartent. Elles sont donc comptabilisées comme des "rebonds", sans que je ne puisse savoir si l'article les a intéressées. Pour dépasser cette limitation, j'ai mis en place une action personnalisée - un événement qui se déclenche lorsqu'un visiteur atteint le bas d'un article. Des événements sont des appels à Piwik - généralement sous la forme de petits bouts de Javascript - qui spécifient que quelque chose s'est passé. Ce quelque chose, c'est à vous de le définir. En l'occurrence, j'ai défini:
- une catégorie ("navigation")
- une action ("EOA" pour "end of article")
- un nom (le titre de l'article)
- une valeur (le temps écoulé entre le moment où la page est chargée et le moment où le bas de l'article est atteint)
var arrivalTime = new Date().getTime();
var lastEndOfArticle = 0;
$(window).scroll(function() {
cooldown = new Date().getTime();
if(
$(window).scrollTop() + $(window).height()
> $(document).height() - parseInt($('footer').css('height'))
& lastEndOfArticle < (cooldown - 30000)) {
timeSinceArrival = (cooldown - arrivalTime)/1000;
lastEndOfArticle = cooldown;
_paq.push([
'trackEvent',
'Navigation',
'EOA' ,
'<?php the_title(); ?>',
timeSinceArrival
])
}
});
Ces modifications vont tout chambouler, à commencer par le fait que les articles lus se distingueront enfin de ceux qui saoulent les visiteurs.
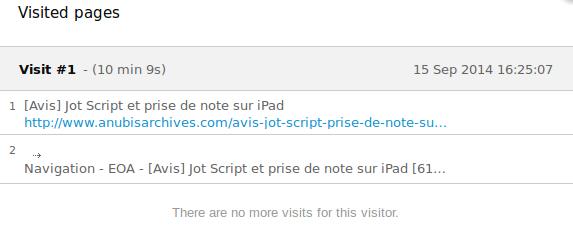
Sans ce système, cette visite aurait été comptabilisée comme un rebond. Or, il s'avère qu'elle a duré plus de 10 minutes.
Il deviendra en revanche difficile de comparer les statistiques des mois précédents avec celles des mois à venir, puisque les règles ont changé. Point positif, le taux de rebond du blog va chuter. Malheureusement, le temps moyen passé sur le site va également dégringoler, puisque les visites d'un seul article ne donnant pas suite à d'autres lectures seront désormais comptabilisées (en admettant que l'article soit lu en entier).
Un certain nombre de faux positifs risque d'apparaître, puisqu'une personne peu intéressée par un article va peut-être prendre la peine d'en vérifier la taille (donc de scroller jusqu'au bas de l'article et déclencher l'événement EOA), avant de s'enfuir en courant. Ces faux positifs pourront heureusement être détectés : si une personne atteint le bas de l'article après 4 secondes sans jamais redescendre, on peut supposer qu'elle ne l'a pas lu en entier. Et franchement, je préfère quelques faux positifs à une horde de faux négatifs qu'on ne peut repérer.
Cerise sur le gâteau, cette modification règle également un autre problème : en arrivant sur un site avec plusieurs articles, certains visiteurs ouvrent plusieurs onglets et les lisent un après l'autre. Pour Piwik, le temps passé sur l'article A est équivalent à [temps passé sur la page A] = [heure à laquelle vous arrivez sur la page B] – [heure à laquelle vous arrivez sur la page A]. Si un visiteur ouvre deux articles à la suite dans différents onglets, le temps passé sur le premier article sera donc équivalent... au temps qu'il mettra à ouvrir le second article. Un résultat erroné. Avec le système d'événements, il sera possible de distinguer le moment où le visiteur ouvre l'article et le moment où il en atteint le pied de page.